
For those unacquainted with GraphQL, it is a method of describing the data your API has and provides a consistent way to query that data. A big benefit of GraphQL is that you have a single schema and endpoint which contains all your data, and clients can query just what they need without your API needing to understand the changing queries used by each consumer. This flexibility can come at a cost when you’re dealing with deeply nested queries and fine-grained access controls; take this query for example:
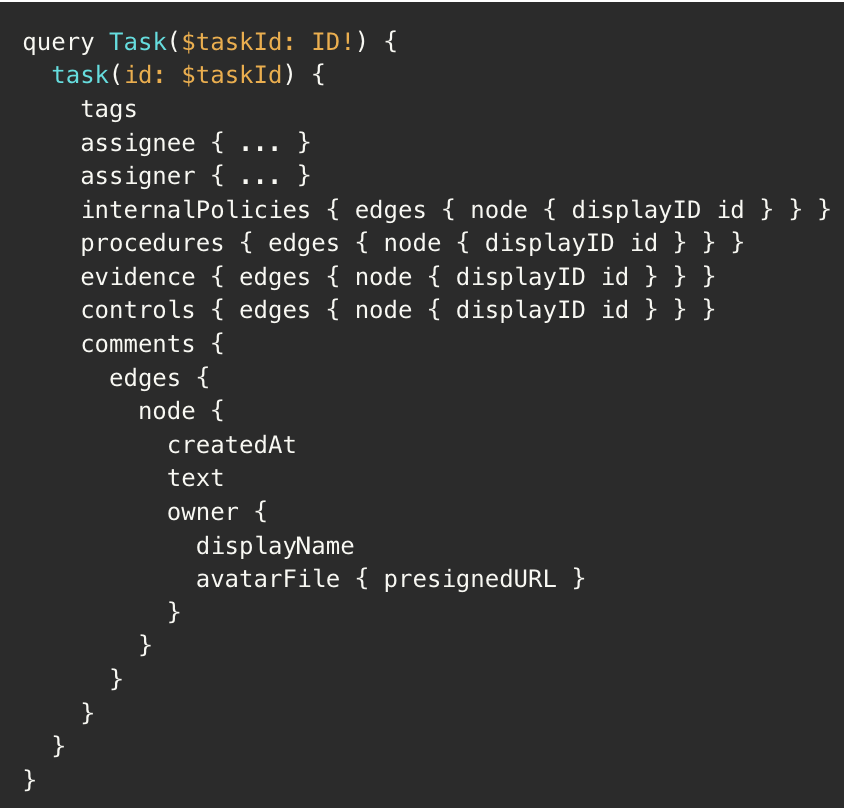
At a glance, this query seems reasonable until you zoom in and notice that each nested edge (internalPolicies, procedures, evidence, controls, comments) can result in multiple subqueries, permission checks, and even unnecessary count queries. As our data set has grown, this query became slower and more unpredictable to the point it was taking around 8-10 seconds to run. This is where our investigation begins!
Initial groundwork
We had a few theories about what could be contributing to the overall query slowness, but we also had some immediately actionable changes we knew would drive better performance, so we went ahead and implemented those:
- Eager Loading – we used Ent’s
CollectFieldsto eagerly load edges based on what the GraphQL query actually needed. This ensured that each edge was queried with a single SQL call, rather than triggering N+1 subqueries for nested objects. - Pagination Enforcement – We introduced strict pagination on all connections. Even if the frontend didn’t yet need limits, the backend enforced them anyway.
These changes shaved off maybe 1-2s at the most, which just wasn't enough. We had two primary theories as to what could be additionally contributing to the slowness but which required us to spend the time to experiment, test, and verify:
- Inter-cloud latency - we decided early on to use NeonDB for our PostgreSQL data store (which they deployed on AWS), but our application services / APIs resided with GCP. Could the cross-cloud traffic be adding latency to our db <-> application interactions? Safe to assume "yes", but how much latency?
- Slow authorization checks – We use OpenFGA to manage fine-grained access control. Could the queries or query types we chose when creating our access checks have bottlenecks?
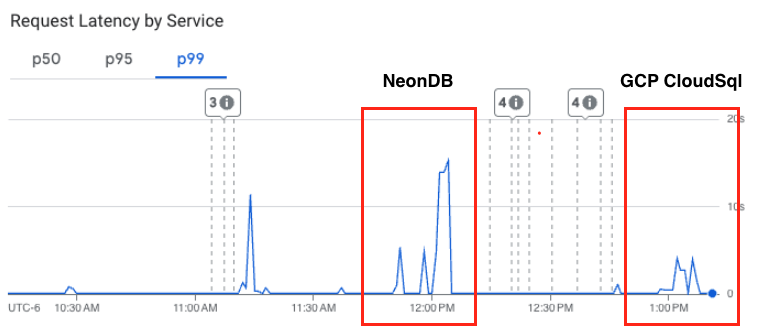
Proving the Inter-Cloud Latency Hypothesis
As we already covered, our database was hosted with NeonDB (AWS us-west-2 in Oregon) while our GraphQL server was running in GCP (us-west-1 also in Oregon). Even though both were in the same general geographic region, the cross-cloud setup meant every query had to traverse the public internet. This meant the traffic originating from our application services had to exit GCP's network and then re-enter AWS' network and then round trip back - adding latency overhead on the round trip communications as well as ingress / egress charges. We had initially thought this penalty wasn't very large but wanted to substantiate it.
To test our theory we repeatedly ran an intentionally expensive query (one that a user would likely never create or use, but made for a great performance benchmark) against our existing setup. Most of the queries' total execution time clocked in over 10 seconds, with some closer to 14 seconds.
We then deployed a Google CloudSQL database instance with similar CPU / RAM specs as our Neon instance but this database was now running in the same cloud provider and region as our runtime. We additionally used private path routing - private connections make services reachable without going through the internet or using external IP addresses. For this reason, private IP provides lower network latency than public IPs. Finally, on top of the already listed changes, we enabled a number of other optional CloudSQL capabilities which we didn't have with Neon such as the data caching capability. The key takeaway to note is that we were not trying to test apples-to-apples, we wanted to know what the total maximum benefit we might reap if we chose to make the switch to CloudSQL including any / all features in CloudSQL which did not exist in Neon.
When we began seeding the new database with similar data as we had tested with in Neon, the performance differences were immediately evident: what previously took ~15 minutes to seed into the database now took about 2 minutes, and we hadn't even gotten to the expensive queries yet. We re-ran the same expensive queries as the first test and the benchmarked 14-second response dropped to just 4 seconds - about 3x faster.
Proving the OpenFGA Query Hypothesis
We initially used OpenFGA’s ListObjects to figure out what a user was allowed to access. It worked well... until it didn’t.
The problem?
ListObjectsdoesn’t support pagination- It’s not optimized for filtering large object sets
- And per FGA’s own docs:
"The performance characteristics of the ListObjects endpoint vary drastically depending on the model complexity, number of tuples, and the relations it needs to evaluate."
We have a fairly complex model which enables some pretty cool permissions features, but due to this complexity, we discovered that for every nested list in the query, we were doing a full permission walk of our graph. That was killing us.
Rethinking our permissions model
We realized something important when investigating: in nearly all of our queries, we already knew the user's organization ID; instead of using ListObjects to find everything they can access, we flipped it:
- Query the DB normally, scoped to the user’s organization
- Use OpenFGA's
BatchCheckto filter that result set down to only the objects the user has access to
This approach worked much better. Rather than traversing the graph for every permission, we just asked: "Can this user see this object?" We implemented the new batch check as a generic Ent query interceptor (simplified for brevity):
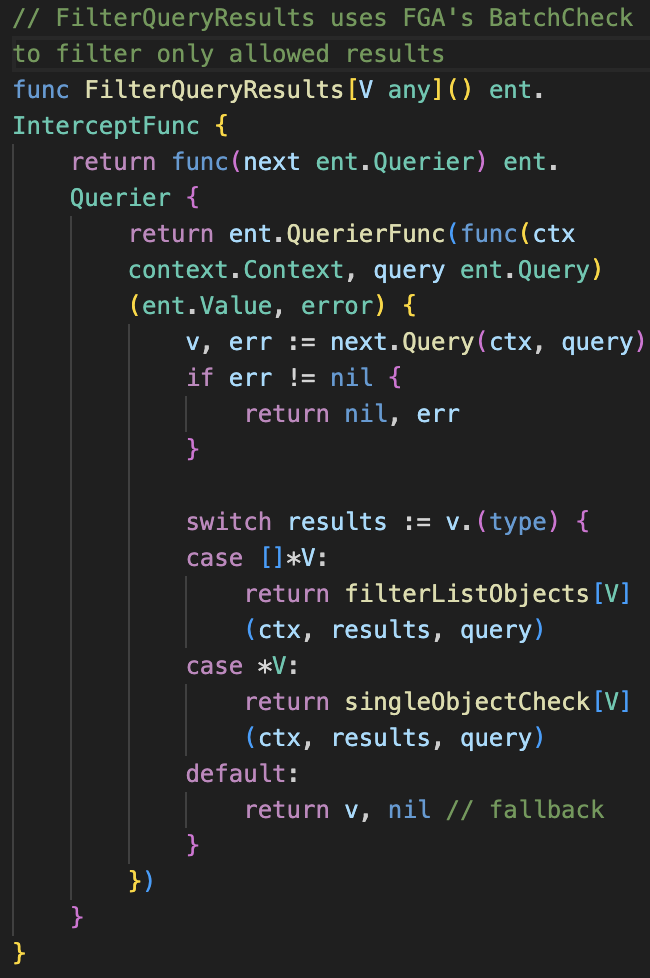
You can check out the full implementation in our open-source code:
Instead of pre-filtering everything with ListObjects, we just pass the result set to BatchCheck and it quickly tells us which IDs are valid for the current user. This reduced our authorization overhead massively, especially on queries with large edge lists like internalPolicies, procedures, and controls.
Bonus: Fixing totalCount with Pagination
If you're using Ent + GraphQL pagination and you adopt this same post-query filtering approach, you’ll likely notice something off: your totalCount will be wrong.
That’s because Ent’s entgql pagination helpers use the original query to calculate the total via .Count(). But in our case, the query results are filtered after the fact (by BatchCheck), which means the count and the actual results are no longer in sync. Unfortunately you cannot simply count the returned nodes because pagination limits mean you’ll only see a subset of what was filtered.
Our fix:
We introduced a custom Count resolver that runs .IDs() instead of .Count():
.IDs()retrieves all matching IDs from the database (before pagination)- Those IDs then flow through our
FilterQueryResultsinterceptor - We return the length of the filtered list as the true
totalCount
Here’s the custom template we use to generate the CountIDs(ctx) function: count.tmpl
We subsequently updated our pagination templates to call CountIDs instead of Count. It’s a small detail, but crucial for keeping pagination metadata correct, especially in access-controlled environments.
Summary
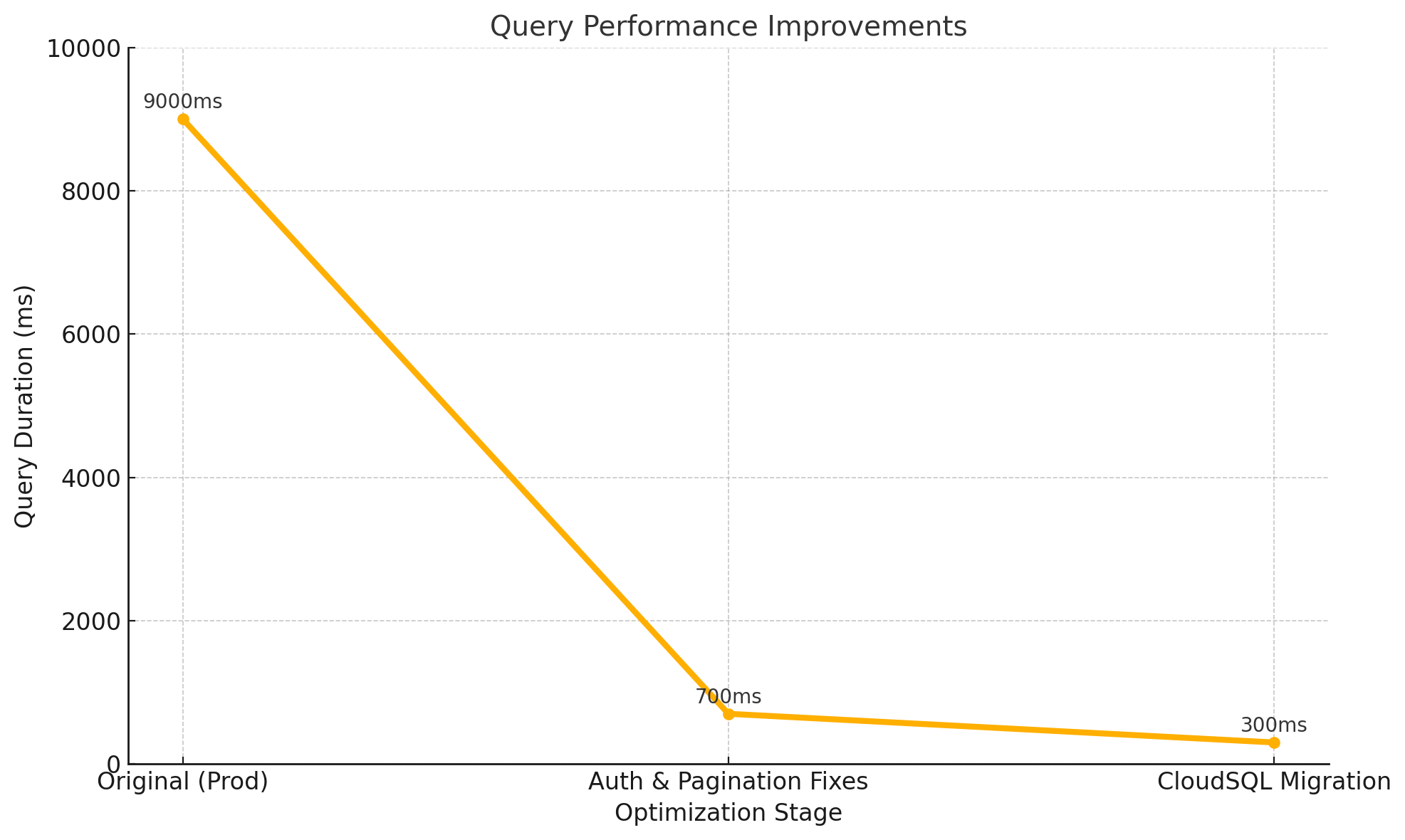
Here is a high level breakdown of our expensive query performance mapped against the various fixes we implemented. The initial ground work shaved off a little of our overhead, the biggest gains came with rethinking our authorization / OpenFGA queries and moving from a ListObjects query to a BatchCheck with filtering, and then we cut the last of our overhead down by moving our PostgreSQL database to run alongside our application services and to connect privately vs. over the public internet.
Key Takeaways
- GraphQL flexibility is great - but costly if you’re not careful
- Always paginate. Even if the frontend doesn’t enforce it, the backend should
- Batch permission checks are your friend.
BatchCheckbeatListObjectsfor our use case by miles - Interceptors are a superpower. With Ent, we could inject this logic cleanly and reuse it everywhere
- Database location matters. Keeping your database in the same cloud and region - and using a private network connection - can meaningfully reduce latency and improve reliability
This wasn’t just a performance win: it was a usability win, a scalability win, and a team productivity win. From optimizing nested GraphQL queries to rethinking our permissions model to moving our database closer to our runtime - every layer mattered.
If you're working on a GraphQL app with complex permissions and growing data sets, take the time to rethink not just how you authorize access, but where your data lives and how it's accessed. Whether you’re chasing down N+1s, fighting cross-cloud latency, or trying to make access control scale - we’ve been there. Check out our code, open an issue, or reach out. We’re always down to trade ideas and share what we’re learning at Openlane.


.png)



